Kreditinstitute können durch die Verwendung von Künstlicher Intelligenz enorme Kostenpotenziale erschließen. Viel zu oft konzentrieren sich Entscheider dabei jedoch nur auf das benötigte KI-Modell – und vernachlässigen zwei wesentliche Aspekte.


Der Einsatz von Künstlicher Intelligenz entscheidet darüber, ob Banken auf der Gewinner- oder Verliererseite stehen.
Partner des Bank Blogs


Die Digitalisierung der Banken – allen voran durch Geschäftsmodelle mit Hilfe von Künstlicher Intelligenz (KI) – ist in aller Munde. Eine Studie der Londoner Economist Intelligence Unit (EIU) ergab beispielsweise, dass 65 Prozent der Führungskräfte im globalen Bankwesen neue Technologien wie Cloud, KI und APIs als den Trend ansehen, der in den nächsten vier Jahren den größten Einfluss auf die Branche haben wird; noch vor Regulierung und veränderten Kundenanforderungen. Darüber hinaus glauben 81 Prozent der Entscheider, dass die Fähigkeit zum Einsatz von KI das Unterscheidungsmerkmal zwischen Gewinner- und Verliererbanken sein wird.
Das Ziel – digitale, durch Künstliche Intelligenz getriebene Institute – ist also klar. Doch die Umsetzung der notwendigen Schritte stockt insbesondere bei KI-Projekten. Der Grund dafür liegt vermehrt darin, dass sich verantwortliche Manager zu stark auf das Endprodukt – ein trainiertes Modell – konzentrieren und die dafür benötigten Vor- und Nachbereitungsschritte vernachlässigen.
Großzügig vorhanden: Das neue Gold der Finanzwelt – Daten
Egal ob Ratingsystem, Chatbot oder Geldwäschekontrolle, das mehrwertgenerierende Modell ist schlussendlich nur so gut wie die Daten, auf welchen es zu einer KI trainiert wurde. Die gute Nachricht: Durch die große Anzahl von digitalen Abläufen innerhalb von Banken sind Daten zunächst in großem Umfang vorhanden. Herausforderungen entstehen hierbei vor allem durch die teilweise eingeschränkte Nutzbarkeit der gespeicherten Datensätze und die zu berücksichtigenden regulatorischen Anforderungen, welche nur spezifische Daten-Merkmale zur Weiterverarbeitung zulassen.

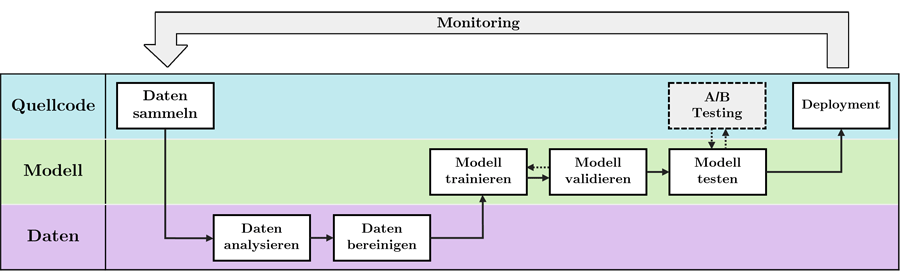
Entscheider müssen neben dem Modell auch ihre IT-Systeme in Form von Quellcode und die zugrundeliegenden Daten berücksichtigen.
Ganz konkret sollten Manager die Sammlung, Analyse und Bereinigung der Datenvorkommnisse ihres Instituts statistischen Profis überlassen, welche auch versteckte Korrelationen zwischen den später benötigten Merkmalen entdecken können. Grundsätzlich können in der Projektplanung allein für die Vor- und Aufbereitung der Daten 60 Prozent der Arbeitszeit eingeplant werden. Sollten sich die bankinternen Teams in dieser Königsdisziplin überschätzen, können je nach Größe des Projekts Wochen oder Monate Verzögerung auftreten.
Tatsächlich Mehrwert in der eigenen IT-Landschaft generieren
Am anderen Ende der Wertschöpfungskette müssen Unternehmenslenker mit validierten und getesteten KI-Modellen umgehen, welche durch ihre Data-Science-Abteilung erstellt wurden. Diese bieten als alleinstehende Artefakte für den Finanzdienstleister und seine Kunden so noch keinen Mehrwert. Denn der magische und letztendlich entscheidende Schritt liegt darin, durch die Integration der entwickelten KI in die produktiven IT-Systeme des Finanzdienstleisters für Unternehmen und Kunden tatsächlich Mehrwert zu schaffen.
Wer sich schon einmal mit der IT-Landschaft von Kreditinstituten beschäftigt hat, weiß jedoch, dass diese in der Regel groß, komplex und manchmal veraltet sind. Die Grundlage für eine erfolgreiche Integration muss demnach in der Regel schon zu Beginn eines Projekts geschaffen werden. Für Entscheider muss also klar sein: Die Einbindung der Projektergebnisse in ihre produktive IT-Landschaft ist kein Selbstläufer und gehört gut vorbereitet – am besten bereits am Anfang der Entwicklung. Sonst droht ein zeitintensives und kostengeladenes Projekt im Zweifelsfall auf den letzten Metern zu scheitern, weil die entwickelte KI nicht von Kunden und Sachbearbeitern verwendet werden kann.
Eine für immer akkurate KI gibt es nicht!
Ende gut, alles gut? Weit gefehlt! Denn wider der verbreiteten Ansicht, dass KI-Anwendungen wie etablierte IT-Produkte nach der Veröffentlichung wie von selbst laufen, müssen die Ergebnisse der eingesetzten KI stetig überwacht werden. Das produktive KI-System basiert schließlich auf historischen Geschehnissen und Datenständen, sodass neue Ereignisse möglicherweise die KI umschiffen könnten. Bei einer KI-gestützten Geldwäscheerkennung könnte das beispielsweise eine neuartige Betrugsmasche sein.
Somit muss auch ein vermeintlich intelligentes System nach einer bestimmten Zeit aktualisiert werden. Andernfalls kann durch fehlerhafte Kategorisierungen und Voraussagen ein großer Schaden für das betroffene Institut entstehen. Die Überprüfung einer KI-Anwendung im laufenden Betrieb kann vor allem durch das Überwachen und Plausibilisieren der Entscheidungsergebnisse mit Hilfe von Kennzahlen durchgeführt werden. Die eingesetzte KI muss in jedem Fall bessere Ergebnisse als menschliche Sachbearbeiter liefern können.
KI-Projekte – eine zyklische Entwicklung mit vielschichtigen Komponenten
Um Prozesse automatisieren und Kosten reduzieren zu können, reicht der eingeschränkte Blick auf die zu entwickelnde KI selbst nicht aus. Entwicklungsprojekte dieser Art sind durch die Alterung der trainierten Modelle zyklisch und müssen durch die Entscheider bereits im Vorhinein so angesetzt werden. Bei der Durchführung der Entwicklung von KI-Anwendungen sollten die verantwortlichen Manager frühzeitig ein besonderes Augenmerk auf die Verarbeitung der vorhandenen Daten und die Integration des endgültigen Modells legen, um den Erfolg ihres Projekts zu garantieren.