

Wie können Big-Data-Technologien Finanzinstitute dabei unterstützen, Risiken zu managen, während das Risikomanagement immer engeren Anforderungen und Regularien unterliegt? Vorteile und Anwendung von Big Data im Risikomanagement von Banken und Sparkassen.

Finanzdienstleistern bietet Big Data viele Chancen, enthält aber auch einige Herausforderungen
Partner des Bank Blogs
Banken und Risikomanagement
Vor einem Jahrzehnt wurde die Welt von einer schweren wirtschaftlichen Krise getroffen. Ursache der Finanzkrise 2007 war unter anderem ein mangelndes beziehungsweise fehlerhaftes Risikomanagement der Banken. Um eine erneute Krise zu vermeiden ist es zwingend notwendig, vorhandene Werkzeuge zur Bewertung von Risiken zu verbessern und wirksame neue zu erschließen. Dies liegt im ureigenen Interesse der Finanzinstitute, wird aber auch von Regulierungsbehörden gefordert und überwacht. Positionen eines Marktteilnehmers, die erhöhten Markt- oder Kreditrisiken ausgesetzt sind, müssen von diesem mit mehr Kapital unterlegt werden. Die Gründe dafür sind vielschichtig und komplex. Entsprechend gehen sehr verschiedene Daten in großer Menge in die Risikoberechnung ein.
Die bestehenden Mittel zur Risikoberechnung werden den gestiegenen Anforderungen heutzutage nur noch zum Teil gerecht. Die aktuellen Aufgaben an die Bewertungsinstrumente sind anspruchsvoller als je zu vor. Dies war für uns Anlass passende Technologien zu suchen und Kompetenzen im Rahmen eines Proof-of-Concept aufzubauen.
Im folgenden Teil des Blog-Beitrags widmen wir uns dem Kontrahenten-Risiko. Für einen Marktteilnehmer besteht dieses dann, wenn einer seiner Geschäftspartner ausfällt, von dem er noch Zahlungen zu erwarten hat. Unter diesen Umständen entfällt der Gewinn und er muss sich durch ein entsprechendes Ersatzgeschäft wieder eindecken (Wiedereindeckungsrisiko).
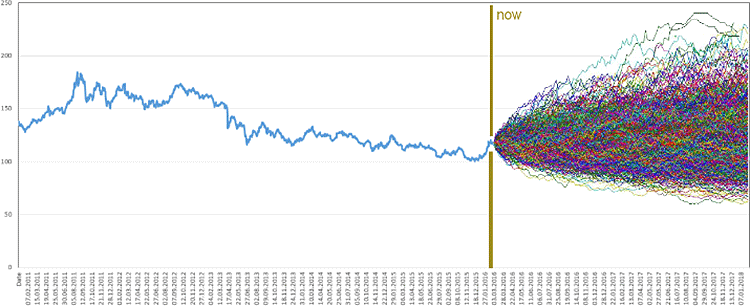
Graph einer beispielhaften Monte-Carlo-Simulation
Eine große Herausforderung in unserem Projekt war das Beschaffen von Eingangsdaten für die Berechnung. Mangels Verfügbarkeit echter Daten haben wir uns entschieden, Werte zu generieren. Diese wurden mit Hilfe von Monte-Carlo-Simulationen verschiedenen Szenarien, sogenannten Zukunftsszenarien, unterzogen. Ihre Ergebnisse bilden die Grundlage der Berechnung von Kennzahlen wie der PFE – Potential Future Exposure.
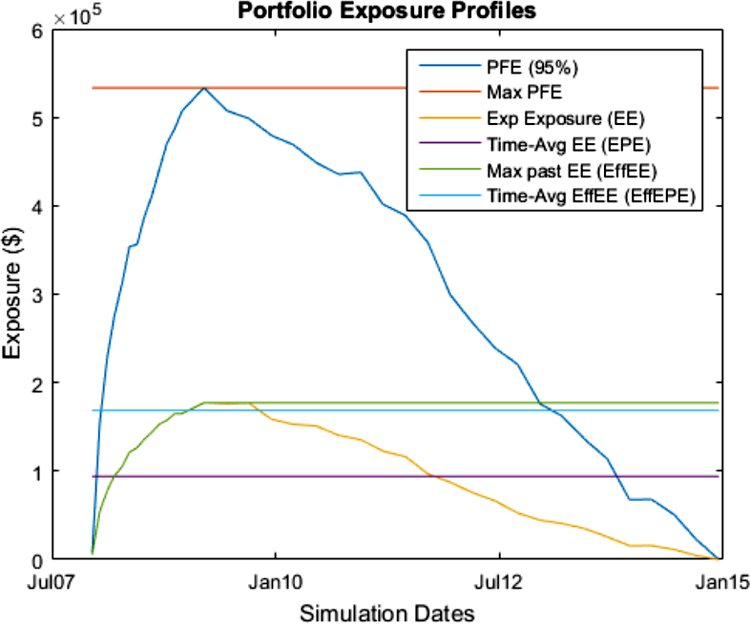
Verschiedene Typen von Portfolio Exposures (offene Positionen) in Relation wie z.B. PFE
Big Data und Risikomanagement
In der technischen Umsetzung dazu haben wir Big-Data-Technologien eingesetzt. Diese eignen sich besonders für Berechnungen im Risikomanagement. Die folgenden drei Schlüsselwörter definieren Big Data:
- Velocity – Geschwindigkeit bei Datentransfer und Datenverarbeitung
- Variety – Umgang mit verschiedenen Datenquellen und Datentypen
- Volume – Umfang der Daten
Nachfolgend ist aufgelistet wie wir uns vorstellen, was diese drei Begriffe im Kontext der Berechnung von Kontrahenten-Risiko konkret im Anwendungsfall einer Bank bedeuten können:
- Velocity: Sachbearbeiter in einer Bank müssen bei neuen Ereignissen schnell handeln und haben es mit immer kürzer werdenden Reaktionszeiten zu tun. Modellberechnungen von Hand werden nahezu unmöglich.
- Variety: Die Heterogenität der Eingangsinformationen erschwert die einheitliche Verarbeitung.
- Volume: Täglich fällt eine Masse von Trades an, die der Sachbearbeiter bei seiner Risikoanalyse berücksichtigen muss.
Diese drei Schlüsseleigenschaften zeichnen Big Data als geeignetes Mittel für die Berechnung des Kontrahenten-Risikos (Counter Party Risk) aus.
Die Anforderungen an die Berechnung von Kennzahlen aus verschiedenen Quellen wie etwa Live-Daten, historischen Daten und simulierten Szenarios, können durch den Einsatz von Big Data erfüllt werden. Die Verarbeitung ist dabei auch vergleichsweise ressourcenschonend.
Infrastruktur einer Big-Data-Anwendung
Die adesso AG hat diese Aufgabe in die Hände von Studenten gelegt und dafür ein Team an zwei Standorten geschaffen. Die technische Umgebung haben die Studenten selbst evaluiert und ausgewählt. Im Big-Data-Umfeld stehen einige Möglichkeiten zur Verfügung. Schließlich hat sich das studentische Team für die Technologie „Apache Spark“ im Prototypen entschieden. Spark ermöglicht ein Zwischenspeichern von Daten, so dass keine aufwändigen Datenbankzugriffe erfolgen müssen. Mit einem Rechnerverbund konnten große Datenmengen auf verschiedene Knoten verteilt und verarbeitet werden. Spark kann seine Stärken besonders mit NoSQL-Datenbanken ausspielen. Daher rundet die Datenbank „HBase“ die technische Infrastruktur des Projekts ab.
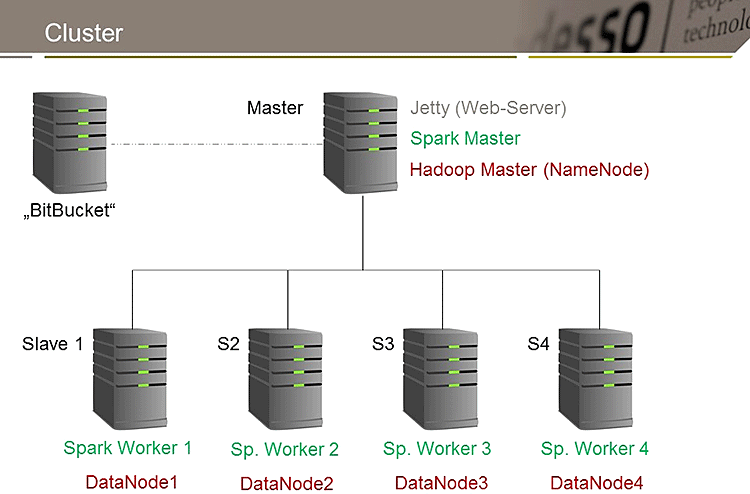
Technische Big Data Infrastruktur mit Mastern/Workern und Nodes
Als Big Data Provider wurde Apache Spark im Cluster aufgesetzt (in der obigen Abbildung grün). Dieses benötigt einen Master, der die number crunching Jobs auf die einzelnen Slaves verteilt. Die Datenhaltung wurde mit Hadoop umgesetzt (im Diagramm rot). Auch hier kommt eine Master-Slave-Architektur zum Einsatz. In diesem Szenario wurden beide Master-Instanzen auf einem Rechner installiert, was aufgrund der unterschiedlichen Ausstattungen ratsam ist. Für die Visualisierung mit einer ansprechenden Weboberfläche wurde zusätzlich ein leichtgewichtiger Web-Server verwendet.
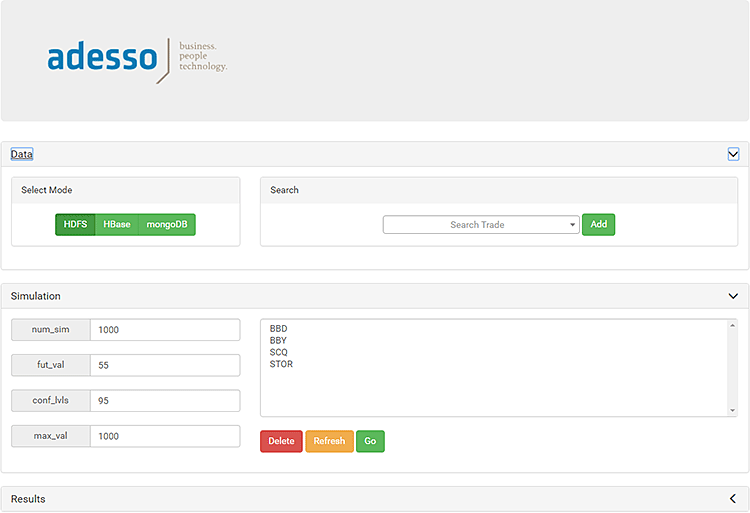
Screenshot der Big-Data-Anwendung mit Funktionalitäten
Ausblick und Fazit
Im Moment realisieren wir in Zusammenarbeit mit „smarthouse adesso financial solutions GmbH“ den Anschluss an Livedaten und an historische Daten für unsere Analysen. Kenntnisse im Bereich Big-Data-Risikomanagement sollen mit der Unterstützung durch smarthouse ausgebaut und gefestigt werden.
Der Use-Case zur Berechnung von Kontrahenten-Risiko lässt sich nach unserer Einschätzung auf viele andere Fachgebiete anwenden. Für die Zukunft sehen wir die Nutzung von Big-Data-Technologien im Bankenumfeld als selbstverständlich an und werden noch weitere Einsatzszenarien entwerfen.

Philip Wilbert
Philip Wilbert ist studentischer Mitarbeiter im Bereich Banking bei der adesso AG und Co-Autor des Beitrags. Er studiert an der technischen Hochschule Mittelhessen in Gießen Informatik.
Partner des Bank Blog – adesso
Mehr über das Partnerkonzept des Bank Blogs erfahren Sie hier.




