

Zur Entwicklung und Inbetriebnahme mehrwertgenerierender Modelle im Bereich der Künstlichen Intelligenz gehören viele wichtige Prozesse. Doch vor allem ein Schritt bildet die Grundlage für ein erfolgreiches KI-Projekt.

Daten sind ein wichtiger Erfolgsfaktor für die Umsetzung Künstlicher Intelligenz.
Partner des Bank Blogs

Entwicklungen im Bereich Künstliche Intelligenz (KI) sind ähnlich wie Softwareprojekte höchst komplex. Insbesondere Banken benötigen deshalb mehrstufige Prozesse, um eine hohe Qualität des Endprodukts sicherstellen zu können. Grundsätzlich lassen sich diese in drei Entwicklungsphasen unterteilen: Data, Model sowie Deployment.
An erster Stelle müssen die zu verwendenden Daten identifiziert, analysiert und für das Training intelligenter Modelle vorbereitet werden. Die hierbei entstandene Datenbasis wird dann in einem iterativen Prozess für das Training und die Validierung bestimmter Modell-Prototypen verwendet. Die voraussichtlich in Produktion akkurateste Modellvariante wird abschließend in die IT-Systeme des Geldhauses eingebunden.
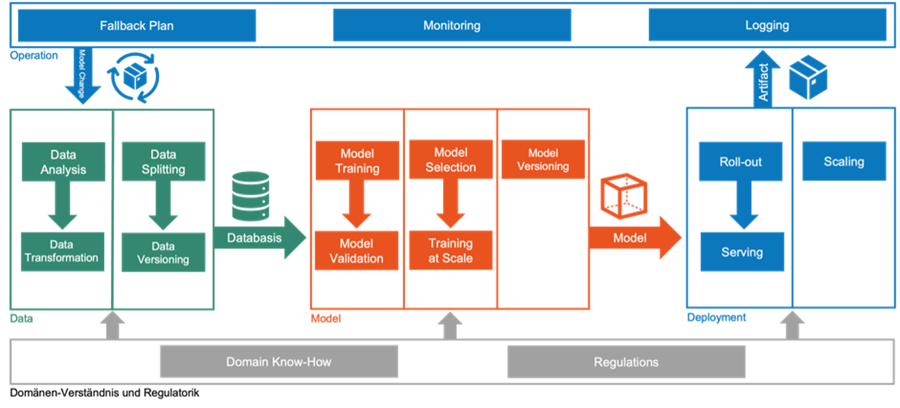
Banken sollten mit Hilfe automatisierter Prozesse für Daten, Modelle und insbesondere produktive Systeme die Qualität ihrer KI-Entwicklungen sicherstellen.
Nachgelagert gilt es für Entscheider, die Ergebnisse des Modells in der produktiven Anwendung zu protokollieren, um auf mögliche Fehlfunktionen reagieren zu können. Dies gilt insbesondere für kritische und direkt mit dem Endkunden interagierende Systeme. Begleitet werden die erstellenden Prozessschritte durch einen stetigen Austausch mit fachlichen Ansprechpartnern, welche durch ihr Domänen Know-how unterstützen, und regulatorische Hürden identifizieren.
Daten bilden Grundlage für weiteres Vorgehen
Bei alledem fällt auf: Die einzelnen Prozessschritte bauen fundamental aufeinander auf. Für ein erfolgreiches KI-Projekt ist somit der vollständige Dreiklang von Daten, Modell und Veröffentlichung zu berücksichtigen. Die Datenvorverarbeitung trifft in diesem Kontext eine besondere Verantwortung. Denn als erster Prozessschritt stellt sie die Weichen für das Training der Modell-Kandidaten.
Je nach avisierter Endanwendung werden unterschiedliche Daten benötigt, welche zunächst in einem Prozess automatisiert zusammengetragen werden müssen. So wird ein Modell zur Betrugserkennung beispielsweise anhand von Transaktionsdaten trainiert, während eine Kreditwürdigkeitsprüfung auf Kredithistorien der Bankkunden aufbaut. Andere Produkte wie intelligente Fonds können auf Basis unstrukturierter Daten – also Bildern, Dateien, Audiomitschnitten und Weiterem – Entscheidungen treffen.
Anzahl von Merkmalen in Daten entscheiden über Differenziertheit des Modells
Die Genauigkeit und Effizienz eines KI-Modells hängen schlussendlich von der Qualität und Quantität der vorliegenden Daten ab, die zum Trainieren des Modells verwendet werden. Je vielfältiger und relevanter die Informationen sind, desto genauer werden die Vorhersagen und Empfehlungen des Modells sein. Im Gegenfall, also bei einer hohen Anzahl irrelevanter, fehlerhafter oder redundanter Daten, wird die Genauigkeit des Modells negativ beeinflusst.
Ein entscheidender Schritt für die Schaffung einer soliden Trainings-Grundlage ist die Datenklassifizierung – auf Englisch Labeling. Um dem Modell zu helfen, die vorhandenen Daten zu verstehen und einzuordnen, werden in diesem Schritt den Daten Informationen oder Identifikatoren hinzugefügt. Einem Algorithmus zur Kreditwürdigkeitsprüfung könnten beispielsweise Labels hinzugefügt werden, um bestimmte Merkmale wie Gehalt, berufliche Position und Kreditvergangenheit zu erkennen. Dieses Vorgehen ist zwar zeit- und kapitalintensiv, ist jedoch für ein zielgenaues Training des Modells unerlässlich.
Qualität der Datenbasis ist technisch und fachlich zu überprüfen
Bankdaten sollten zunächst anhand einer Reihe von Faktoren analysiert werden, darunter die Einheitlichkeit, Aktualität, Korrektheit und der Umfang der Datensammlung. Hierbei kommen unterschiedliche Techniken zum Einsatz, welche die Daten formal in die richtige Form bringen und teilweise sogar fachlich prüfen.
In diesem Kontext sollten die Daten zunächst hinsichtlich ihres Formats validiert werden. Dies beinhaltet eine automatische Prüfung der Datenfeldern, die insbesondere statistische Ausreißer oder fachlich sinnlose Werte identifiziert, beispielsweise eine Textkette in einem Datumsfeld. Mit Hilfe von Algorithmen, die bestimmte Muster oder Normen erkennen und Ausnahmen von diesen Mustern hervorheben, können diese Analysen zunächst automatisiert durchgeführt werden.
Domänen Know-how macht interdisziplinäre Teams zu zentralem Faktor
Ergänzend dazu sind weiterhin manuelle Tests notwendig, welche durch Stichproben schwerwiegende fachliche Fehler in den Daten identifizieren. Dies kann beispielsweise für bestimmte Kundengruppen oder Betragsgrenzen gelten, die noch nicht automatisiert überprüft werden. Um tatsächlich sinnvolle Modelle mit großteilig fehlerfreien Daten trainieren zu können, besitzt somit die Einbindung der Fachabteilungen in diesem vorgelagerten Schritt besondere Relevanz. Denn Fehler in den Daten können nur automatisiert identifiziert werden, wenn die grundsätzlichen fachlichen Leitplanken mit Hilfe von Domänen Know-how der entsprechenden Experten festgelegt wurden.
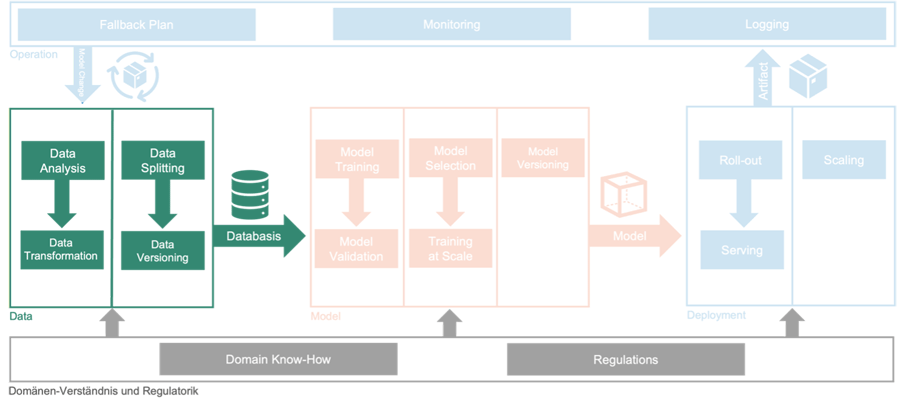
Geldhäuser sollten insbesondere Daten-Prozesse am Anfang von KI-Projekten priorisieren. Damit einher geht die fachliche und regulatorische Betrachtung des Datenhaushalts.
Dies gilt auch und besonders für die regulatorische Einschätzung des KI-Projekts. Durch die intensive Auseinandersetzung mit möglichen Richtlinien und Einschränkungen sollten Manager bereits in dieser Projektphase festlegen, welche Daten zu welchem Zweck verwendet werden können. Dadurch sind bereits vor dem Training die wichtigsten Grundlagen für ein Modell geschaffen, welches auch unter Compliance und Regulatorik Bestand hat. Somit ist für tatsächlich effektive KI-Projekte eine enge Verzahnung zwischen Technologie und Fachlichkeit unerlässlich. Interdisziplinäre Teams bestehend aus Programmieren, Datenwissenschaftlern, Branchenexperten und Juristen können für dieses Vorhaben eine zentrale Rolle spielen, weil sie den natürlichen Austausch zwischen Experten unterschiedlicher Bereiche fördern.
Wer Daten nicht umfassend vorverarbeitet, zahlt doppelt
Mit einer sorgfältigen Sammlung und Vorverarbeitung von Bankdaten schaffen Finanzdienstleister die Basis für zuverlässige KI-Modelle. Vor allem aber vermeiden Entscheider durch diese solide Grundlage hohe Folgekosten, die bei einer hohen Anzahl fehlerhafter Daten im Trainings-Prozess entstehen können. Entscheidend hierbei ist die Einbindung fachlicher Experten hinsichtlich regulatorischer Fragestellungen und bankspezifischer Fallstricke – beispielsweise durch die Einsetzung fachübergreifender Teams.
