


Um für Datenflut, ESG und demografischen Wandel gut aufgestellt zu sein, muss das Datenmanagement in einer Bank systematisch aufgebaut sein. Das Beispiel der Berlin Hyp zeigt, wie mit einem neuen Bereich dieser nächste Schritt der Digitalisierung gelingen kann.

Mit dem neuen Bereich Datenmanagement und einer breit angelegten Bildungsoffensive für die Gesamtbank geht die Berlin Hyp den nächsten Schritt der Digitalisierung.
Partner des Bank Blogs

Die Business- und IT-Architektur in der Finanzwirtschaft wird seit Jahrzehnten nach Prozessen und Anwendungen strukturiert. Daten rücken erst seit einiger Zeit stärker in den Fokus. Allein schon aufgrund ihrer ständig stark wachsenden Menge aber auch aufgrund ihrer zunehmenden Bedeutung in den Geschäftsprozessen, für die Risikosteuerung und die Nachhaltigkeit (Stichwort CSRD). Viele aktuelle Entwicklungen in Banken sind demgemäß stark datengetrieben. Dennoch fehlt den meisten Instituten bis heute ein ganzheitliches Konzept zum Datenmanagement.
Eine neue Sicht ist erforderlich
Die Berlin Hyp hat – als gewerblicher Immobilienfinanzierer mit um die 600 Mitarbeiter – in den letzten Jahren ihre Geschäftsprozesse hinterfragt, sequenziert, neu geplant und digitalisiert. Hierbei wurde auch die Aufbauorganisation angepasst und das Datenmanagement 2020 als neuer Bereich mit drei Abteilungen gegründet.
Dahinter steht die Überzeugung, dass der effiziente und effektive Umgang mit Daten zunehmend zur Kernkompetenz für die weitere Digitalisierung wird. Denn bereits ein einzelnes Geschäft in der Immobilenfinanzierung generiert viele Tausend Datenpunkte. Als neues Denk- und Zusammenarbeitsmodell hat sich in der Berlin Hyp das sogenannte Datenhaus etabliert. Hier werden die erforderlichen Bausteine für ein erfolgreiches Datenmanagement in einem einfachen Schema zusammengeführt.
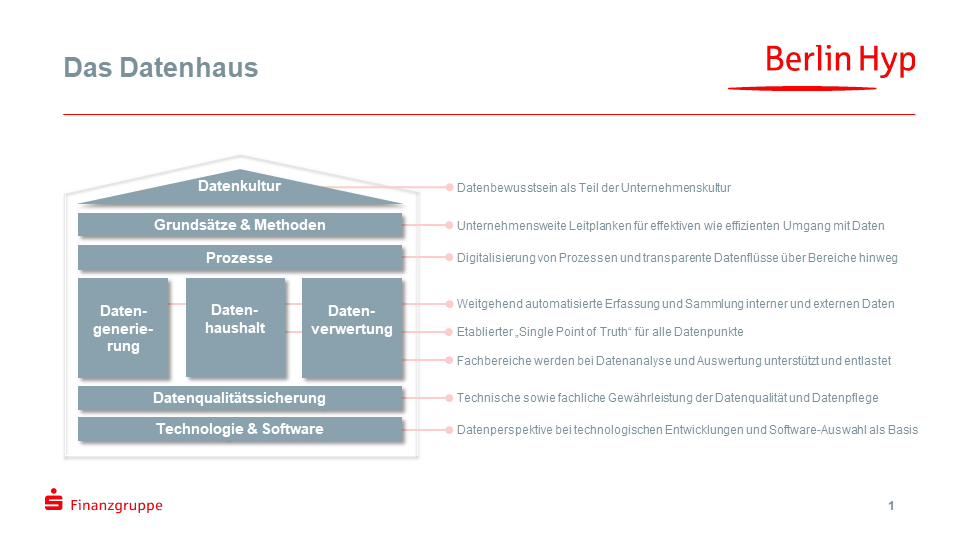
Das Datenhaus der Berliner Hyp mit seinen achten Bausteinen hilft als einfaches Schema das Datenmanagement ganzheitlich zu denken und nichts zu vergessen.
Ein vielfältiger Mix an Kompetenzen und Erfahrung ist gefragt
Um ein intelligentes Datenmanagement zu schaffen, bedarf es Zweierlei: Zum einen die profunde Kenntnis über die bankfachlichen Prozesse sowie deren relevante Entscheidungsparameter. Zum anderen die Methoden-Kompetenz, Daten zu erfassen, zu verarbeiten, in einem zentralen Haushalt zu organisieren und in einem Folgeschritt weiter zu analysieren und somit neue Erkenntnisse zu gewinnen. Die Simulationsfähigkeit wird hierbei für Banken immer wichtiger. Diese Fähigkeit gibt es aber nur mit einem aufgeräumten Datenbestand und davon sauber getrennten Arbeits- und Berechnungsmethoden, denn Simulationen sind 90 Prozent Daten, 5 Prozent Methodik, 4 Prozent Parameter und 1 Prozent Dashboard.
Folglich kommen die meisten Mitarbeiter für den neuen Bereich aus vielen anderen Disziplinen der Bank wie Kredit, Finanzen, Risiko, IT oder Wertermittlung, um das Expertenwissen und die fachliche Erfahrung ins Datenmanagement einzubringen – ergänzt um einige wenige Neuzugänge mit Schwerpunkt Data Sciene. Hinsichtlich Alter, Erfahrung, Ausbildung, Firmenzugehörigkeit, Lebens- und Karrierezielen könnte der neue Bereich unterschiedlicher kaum sein. So gilt es neben den Daten auch unterschiedliche Generationen, Kulturen und Ansprüche zu managen.
Dieses Vorgehen verursacht am Anfang Aufwand durch Integration und Zusammenwachsen, ist vermutlich aber für die meisten Banken realistisch und empfehlenswert. Denn die wenigsten Häuser werden gleich in einem Schwung 20 oder 40 neue Data Scientist einstellen können. Zumal diese auf dem Arbeitsmarkt kaum zu finden wird. Und sollte man als Arbeitgeber doch die Chance haben, müsste den neuen Data Scientist die Fachlichkeit beigebracht werden. Was vermutlich genauso dauern würde, wie andersherum.
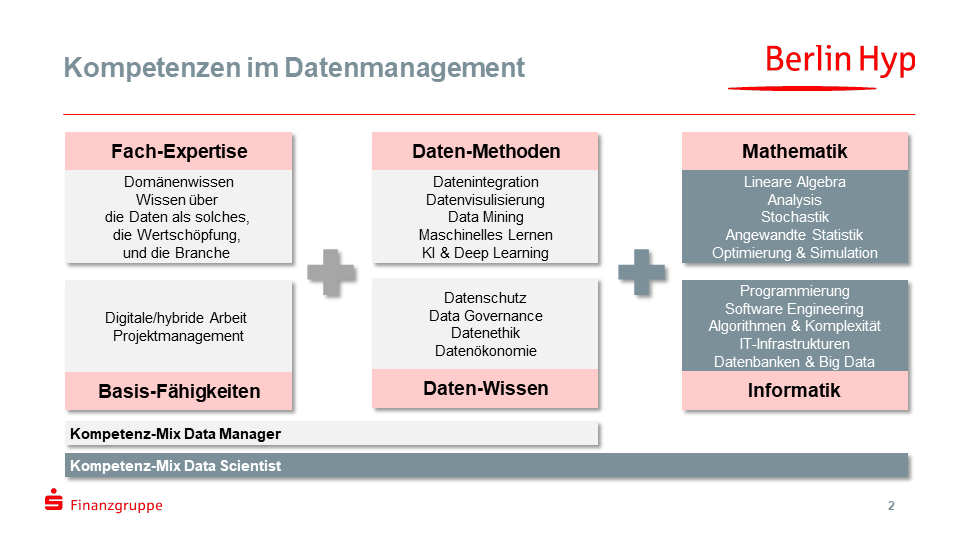
Datenmanagement benötigt einen vielfältigen Mix an Kompetenzen und ist relativ neu als Disziplin, daher ist meist Aufbau von Kompetenzen erforderlich.
Drei neue Jobprofile für die Datenarbeit
Die bankfachlichen Kenntnisse sind im Datenmanagement durch das Zusammenführen bestehender Disziplinen also ausreichend vorhanden sind. Entsprechend gilt es für den neuen Bereich, die Mitarbeiter bezüglich methodischer und technologischer auf einen gemeinsamen Stand zu bringen. Im Kreditprozess und im Risikomanagement gibt es beispielsweise seit „Banker-Generationen“ bekannte und einheitliche Standards. Im Datenmanagement müssen diese meist erst noch geschaffen werden. So strukturiert sich der Bereich mit seinen 50 Mitarbeitern zukünftig in drei neuen Job-Profilen:
- Data Manager
- Advanced Data Manager
- Data Scientist
Data Manager sind dabei stärker in die Linie eingebunden, übernehmen die Datenarbeit an den Geschäftsprozessen und haben eine tiefe Fachkenntnis. Advanced Data Manager verfügen darüber hinaus über eine Spezialisierung in einem bestimmten Daten-Thema (wie ESG-Daten, Kunden-Daten, Schnittstellen, Datenqualität, Automatisierung, etc.). Data Scientists hingegen arbeiten stärker projektorientiert an Methoden sowie Standards und haben eine breite Basis in Mathematik, Statistik, Informatik und Software-Engineering. Für diese drei Profile wurde in der Berlin Hyp über mehrere Monate mit einer Hochschule ein breit angelegtes Qualifizierungsprogramm geplant, das nun über zwei Jahre läuft.
Neben diesen drei Profilen kann in individuellen Beratungsgesprächen auch ein persönliches Programm zusammengestellt werden. Dies kann und wird auch gern von zahlreichen Mitarbeitern aus anderen Bereichen (derzeit 35) wahrgenommen, die ebenfalls am Lernprogramm teilnehmen können. Spezialisierungsthemen können im Bereich Business Intelligence, Data Engineering, Data Mining oder Methoden zur Visualisierung sein. Künstliche Intelligenz, bzw. maschinelles Lernen oder die Programmiersprache Python stehen auch auf dem Programm. Das Einbeziehen von Mitarbeitern aus anderen Bereichen ist entscheidend, um mittelfristig einen abgestimmten Datenhaushalt und End-to-End-Prozesse zu ermöglichen sowie langfristig eine übergreifende Datenkultur zu entwickeln.
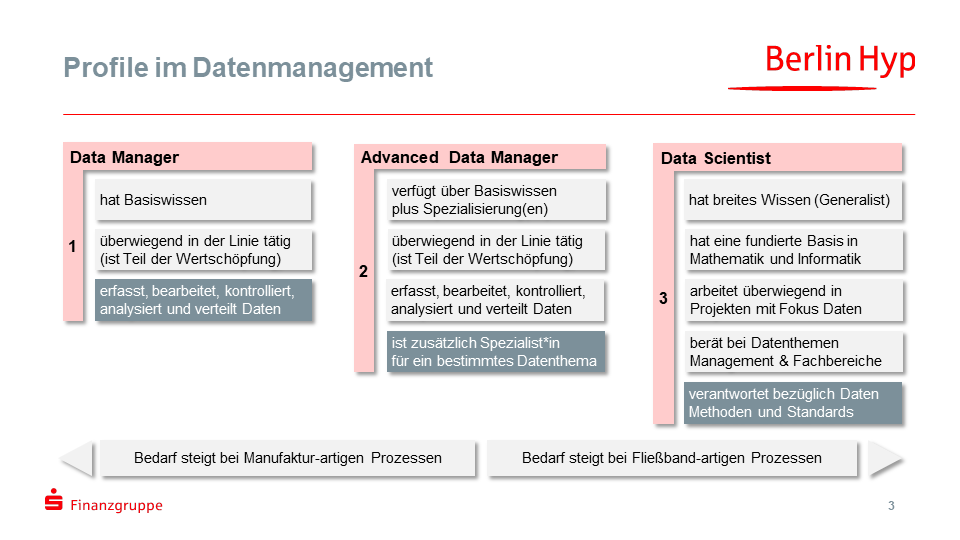
Datenmanagement erfordert neue Profile – ein möglicher Dreiklang zur Orientierung
Nach Corona Individualität erhöhen und Perspektiven schaffen
Die Mitarbeiter entscheiden dabei selbst, ob sie Prüfungen ablegen möchten. Von der bloßen Teilnahme, über die Zertifizierung bis zur eigenständigen Fortführung als vollwertiges Studium in Data Sciene (Bachelor, Master und ab 2024 vermutlich auch MBA) ist hier durch weitsichtige Konzeption und Modularisierung alles möglich. Dadurch werden individuelle Möglichkeiten geschaffen, statt ein einheitliches Schema für alle festzulegen. Durch die digitale Plattform und die Strukturierung über Bausteine ist der Mehraufwand für die Individualisierung gering.
Ein Großteil der Qualifizierung kann in digitalen Einheiten selbständig online nach eigenem Zeitbedarf absolviert werden. Das Programm ist mit kurzen Videos, Podcasts, kleinen Aufgaben und externen Links zur Vertiefung modern und abwechslungsreich gestaltet. Es kann je nach Ambition unterschiedlich intensiv genutzt werden. Die Module sind als ganzheitliche Lernreise auf den Bedarf der Berlin Hyp zugeschnitten und auf jedem digitalen Endgerät wie Smartphone, iPad, PC bis hin zum Großbildfernseher nutzbar. Workshops in Kleingruppen, Live-Veranstaltungen zum Austausch sowie individuelles Coaching ergänzen die Programme und schaffen in der Post-Corona-Zeit neue Anreize und Fixpunkte für Kooperation, Kreation und Interaktion.
Datenmanagement intern neu denken und aufsetzen
Bisher galten Daten oft als das neue Öl oder das neue Gold. Dieses Bild ist nicht mehr passend, für Banken passte es eigentlich nie. Daten sind für Banken das lebensnotwendige Wasser. Sie laufen quer durch die Gesamtbank, Prozesse sind ihre internen wie externen Transportflüsse, IT-Systeme ihre Ökosysteme und Lebensräume. Daten sollten also ähnlich gedacht und aufgestellt sein wie die IT. Die IT ist oft nach Anwendungen und Architektur geclustert, das Datenmanagement nach Prozessen und Strukturen. Diese beiden Perspektiven ergänzen sich also gut und ergeben erst zusammen ein Ganzes. Ein Head of Data oder eine Stabsstelle für Einzelkämpfer sind hierbei aber nur halbherzige Feigenblätter und bringen nicht den Fortschritt, den viele Häuser bezüglich Daten benötigen.
Banken ohne ein gut aufgesetztes Datenmanagement werden in der weiteren Digitalisierung viel Potential, Zeit und Geld verlieren. Dies meint nicht, dass durch ein Datenmanagement neue Geschäftsmodelle und Erlösquellen entstehen (den Beratern bitte also nicht alles glauben). Sondern, dass bei einem unstrukturierten Datenmanagement die Prozesskosten explodieren werden, da aufgrund der wachsenden Datenmenge die Komplexität exponentiell ansteigt. Denn Daten haben i.d.R. m:n-Beziehungen keine 1:1-Beziehungen. Die Lösung hierzu liegt in den Fähigkeiten der eigenen Mitarbeiter nicht mehr nur mit den Daten zu arbeiten, sondern auch an den Daten.




